|
Create ML. Text Classifier.
В статье рассказано о тестировании программы Text Classifier (классификатор текста), входящей
в состав Create ML. Create ML - это инструмент создания моделей Machine Learning (машинного обучения) от компании Apple.
Возьмем DataSet (набор данных) с сайта Kagle, предназначенный для тренировки моделей классификации текста "2225 documents from the BBC news website classified by category"
(225 документов с новостного сайта BBC, сгруппированных по категориям) и протестируем программу на нем.
Новости в DataSet сгруппированы по категориям: business, entertainment, politics, sport, tech. Usability этого DataSet 9.4.
Все записи DataSet находятся в одном csv файле. Cтруктура данных этого файла не соответствует требованиям Text Classifier. Для решения этой проблемы был написан Python скрипт, который читает файл DataSet, выделяет новости, формирует из них отдельные файлы и разносит их по папкам с именами категорий. Скрипт можно загрузить. Для использования скрипта надо прописать в его исходном тексте путь к вашей стартовой папке. Затем script следует выполнить, например, в Jupyter Notebook. Text Classifier предоставляет возможность тренировки моделей с применением трех разных алгоритмов: Maximum entropy, Conditional random field, Transfer learning. Запустим Text Classifier и создадим модели по каждому из алгоритмов. После завершения задач оценим качество созданных моделей. Какие параметры модели будем оценивать? Прежде всего это: 1. Структура папок проекта.
Перед запуском программы Text Classifier необходимо загрузить
DataSet и
Python Script.
Затем следует подготовить структуру папок c текстовыми файлами новостей. На этих файлах Text Classifier будет тренировать и тестировать модель.
Для создания структуры папок необходимо распаковать Python script и DataSet. Затем следует открыть script в Jupyter Notebok,
Visual Studio Code или в любой другой среде разработки и отредактировать путь к вашей стартовой папке, например, BBS News. Сохраните изменения и выполните script.
По завершении работы скрипта вы получите стрктуру папок, готовую для запуска Text Classifier.
Папка train содержит 1850 файлов, предназначенных для тренировки и проверки модели. Папка test содержит 375 файлов для тестирования.
Структура папок показана на рисунке ниже.
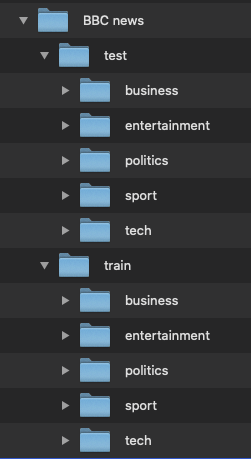
Рис. 1.
2. Тренировка модели по алгоритму "Maximum Entropy".
Описание теоретических основ алгоритма приведено в статье
Using Maximum Entropy for Text Classification
(Использование максимальной энтропии для классификации текста). На стартовом экране Text Classifier выберем radio box "Maximum entropy"
и пути к папкам тренировки и тестирования, затем запустим Text Classifier. Програма выполнит тренировку и тестирование модели.
По окончании работы Text Classifier выведет результаты, показанные на следущем рисунке.
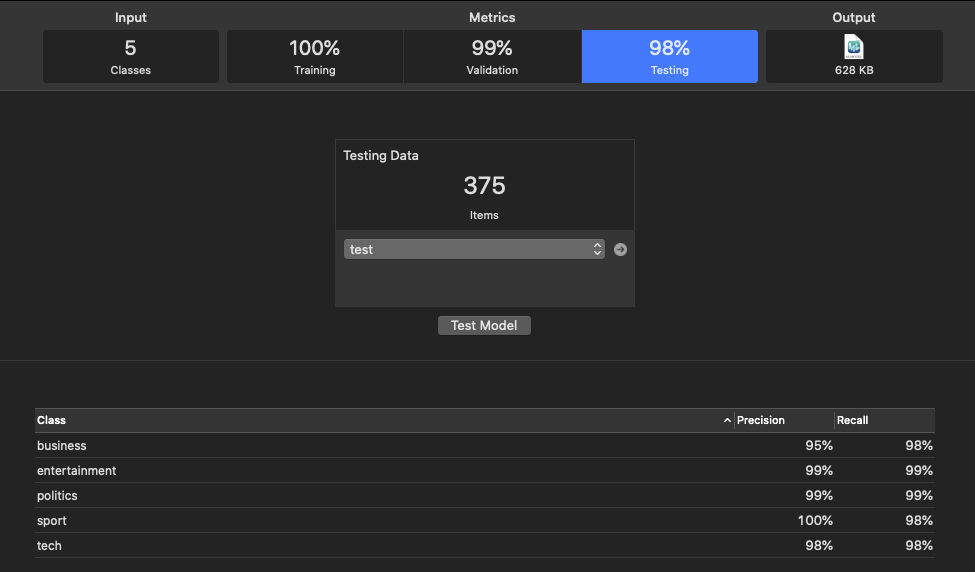 Рис. 2.
Значения Pecision и
Recall характеризуют точность классификации моделью каждого класса.
Определения этих показателей были даны в статье
"Create ML. Трансферное обучение".
Назначение вкладок в верхней части экрана определено в статье Create ML. Sound Classifier.
Размер модели и время тренировки:
3. Тренировка модели по алгоритму "Conditional Random Field".
Описание теоретических основ алгоритма можно найти, например, здесь.
На стартовом экране Text Classifier выберем radio box "Conditional random field" и пути к папкам.
Запустим Text Classifier, выполним тренировку и тестирование модели.
По окончании работы программа выведет результаты, показанные на следущем рисунке.
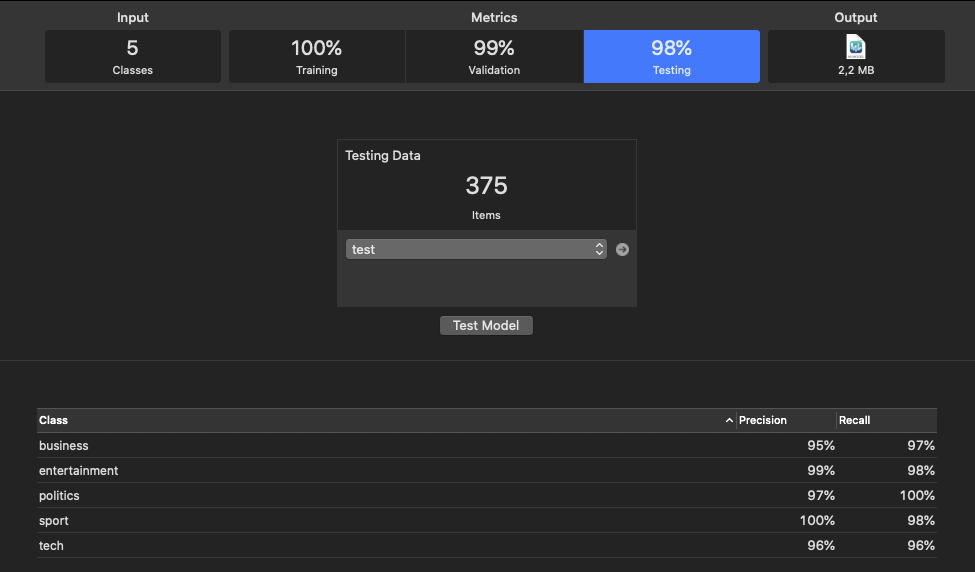 Рис. 3.
Значения Pecision и
Recall характеризуют точность классификации моделью каждого класса.
Размер модели и время тренировки:
4. Тренировка модели по алгоритму "Transfer Learnig".
На стартовом экране Text Classifier выберем radio box "Transfer learnig" и пути к папкам.
Запустим Text Classifier, выполним тренировку и тестирование модели.
По окончании работы программа выведет результаты, показанные на следущем рисунке.
Рис. 4.
Размер модели и время тренировки:
Евгений Вересов.
30.05.2020 года.
|

|
|
