|
Create ML и трансферное обучение.
В Xcode 11.3,
компания Apple выделила Create ML в отдельный инструмент и поместила в нем ряд шаблонов, предназначенных для обучения (тренировки) моделей.
Это шаблоны классификатора изображений, детектора объектов, классификатора звука (audio data) и ряд других.
Возьмем классификатор изображений и создадим модели для следующих наборов данных (DataSet):
Затем оценим качество этих моделей. Все DataSet скопированы с сайтов Kaggle и GitHub «как есть» без изменений.
Какие параметры моделей будем оценивать? Прежде всего это:
Хочу поблагодарить команду Ray Wenderlich за его книгу Machine Learning by Tutorials . Это очень хорошая книга.
1. Последовательность обучения в Create ML.
1.1 Как формируется модель?
Процесс тренировки модели при трансферном обучении состоит из двух этапов.
На первом этапе созданная в компании Apple модель - «VisionFeaturePrint_Screen» сканирует DataSet пользователя и извлекает
2048 свойств (extracting feature) из каждого изображения. Эти свойства полностью описывают изображение.
Такой прием позволяет не обучать модель с «нуля».
Что происходит дальше? На втором этапе Create ML применяет выделенные свойства как входы для создания новой модели логистической регрессии. Обучение модели алгоритму логистической регрессии проходит сравнительно быстро. В итоге общее время создания модели получается относительно небольшим. Значит ли это, что трансферное обучения в Create ML подходит для любого DataSet? Нет. VisionFeaturePrint_Screen это мощна модель, обученная на большом количестве классов, однако, существуют DataSet для которых она не подходит.
1.2. Проверка и тестирование моделей.
Validation dataset.
Для проверки модели Create ML выделяет из DataSet 5% изображений.
На этом подмножестве модель не тренируется. Назовем такой набор данных проверочным (validation dataset).
Операция выделения этого набора выполняется Create ML автоматически.
Однако у пользователя есть возможность установить собственный набор validation.
Но для чего нужен validation dataset?
Дело в том, что при обучении модели пользователь может варьировать ряд параметров: blur, crop, rotate, maximum iterations и так далее.
Validation dataset будет отображать качество модели при разных значениях этих параметров.
О качестве модели подробно расскажем ниже, в разделе 1.3.
Test dataset.
Кроме проверочного набора может существовать еще и тестовый набор данных (test dataset).
Create ML предоставляет возможность пользователю самостоятельно определить место нахождения этого набора изображений.
Тестовый набор не участвует в обучении и проверках.
Пользователь проверяет готовую модель на этом наборе как на реальных данных.
1.3. Оценка качества модели.
Для определения понятия «качество модели» воспользуемся изображениями из DataSet «Fruits 360».
Показатель precision.
При обучении, проверке или тестировании модель просматривает все изображения и прогнозирует принадлежность их к тому или иному классу.
Если модель пытается поместить изображение лимона в класс яблок, - это ложное предположение.
Значение показателя precision будет высоким, если мало ложных предположений, и низким,
если модель часто ошибается.
Показатель recall.
Это еще один показатель качества.
Предположим, что изображение принадлежит к классу яблок, но модель ошибочно пытается поместить его в какой-то другой класс.
Recall подсчитывает, сколько изображений яблок модель нашла в классе яблок.
Если модель пропустит много изображений, значение recall будет низким.
Precision, recall, размер модели - это важные характеристики качества модели.
2. DataSet Sign Language Digits. Цифры языком жестов.
В этом разделе мы будем обучать модель на DataSet «Sign Language Digits».
Изображения в этом наборе - это жесты, изображающие цифры от 0 до 9.
Размер изображений 100 x 100 пикселей, цвет RGB. Набор оформлен в виде множества jpg файлов.
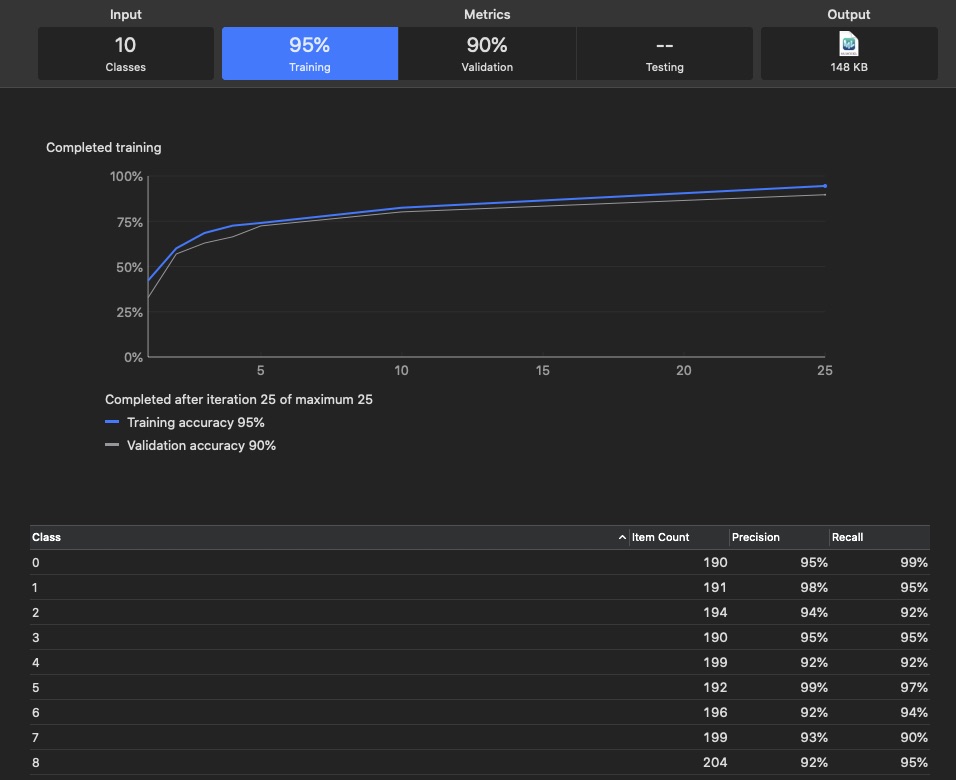
Число изображений — 2062, число классов - 10. Вот примеры некоторых изображений.
Значения Precision и Recall для каждого класса после обучения показаны на рисунке 1.
Рис. 1.
А это параметры обучения: 3. DataSet Fruits 360. Фрукты.
В этом разделе мы будем обучать модель на DataSet «Fruits 360».
Изображения в этом наборе - это фрукты.
Размер изображений 100 x 100 пикселей, цвет RGB.
DataSet оформлен в виде множества jpg файлов.
Обучающий набор содержит 60498 файла с изображениями.
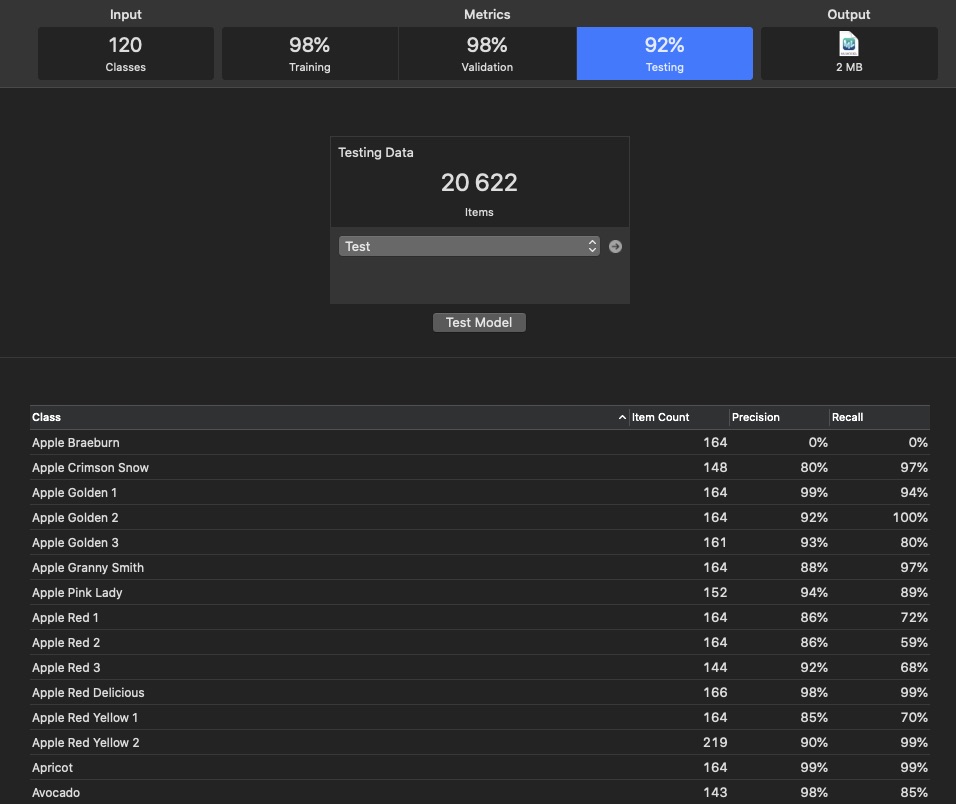
Число классов - 120. Имеется тестовый набор содержащий 20622 файла. Вот примеры некоторых изображений.
Значения Precision и Recall для каждого класса после тестирования модели показаны на рисунке 2.
Рис. 2.
А это параметры обучения: 4. DataSet MNIST.
В этом разделе мы будем тренировать модель на DataSet «MNIST».
Изображения в этом наборе это цифры от 0 до 9.
Размер изображений 28 x 28 пикселей, цвет Gray.
Набор оформлен в виде множества PNG файлов.
Число файлов в тренировочном наборе — 60000. Число классов — 10.
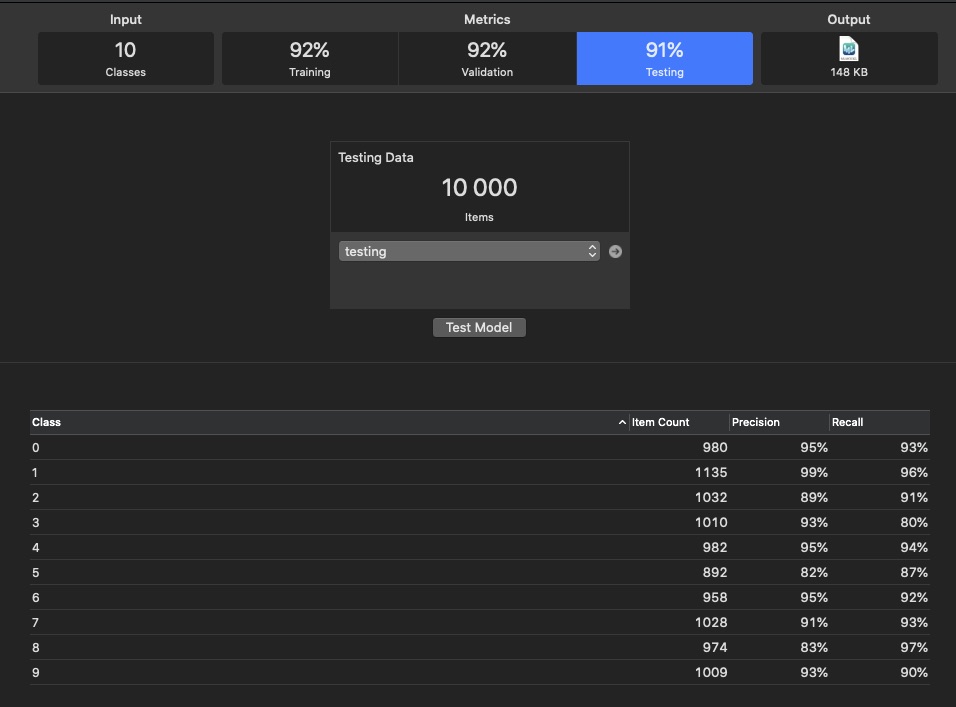
Тестовый набор содержит 10000 изображений. Вот примеры некоторых изображений.
Значения Precision и Recall для каждого класса после тестирования модели показаны на рисунке 3.
Рис. 3.
А это параметры обучения: Подведем итоги.
1. Обратите внимание на очень небольшой размер моделей, создаваемых Create ML.
Происходит это потому, что VisionFeaturePrint_Screen является частью операционной системы, начиная с iOS 12.
2. Определяющую роль в качестве модели играют подготовка набора данных (DataSet),
выбор алгоритма и параметров обучения. Например, качество модели,
созданной на сбалансированном наборе MNIST вполне удовлетворительное, cмотрите рис.3.
3. Если вы серьезно решили заниматься Deep Learning, вам потребуется компьютер с графическим процессором (GPU).
Другим вариантом может быть аренда времени на серверах Amazon, Google или Microsoft.
Надеюсь, что статья окажется полезной.
Евгений Вересов.
30.01.2020 года.
|

|
|