|
Create ML. Sound Classifier.
В статье рассказано о тестировании программы Sound Classifier (классификатор звуков), входящей
в состав Create ML. Create ML - это инструмент создания моделей Machine Learning (машинного обучения) от компании Apple.
Возьмем DataSet (набор данных) Environmental Sound Classification 50 (классификация звуков окружающей среды) и протестируем программу на нем.
Этот набор данных с сайта Kagle, предназначенный для тренировки моделей, включает 50 классов звуков окружающей среды. Каждый класс содержит по 40 wav файлов длительностью 5 секунд.
Все файлы DataSet находятся в одной папке.
Однако, Sound Classifier требует разделения классов по папкам. Для решения этой проблемы был написан Python скрипт, который создает папки с именами классов и наполняет их файлами. Скрипт можно загрузить. Для использования скрипта надо прописать в его исходном тексте пути к вашим папкам, затем выполнить его. Запустим Sound Classifier и создадим модель для нашего набора данных. По завершении задачи оценим качество созданной модели и инструментальные возможности программы. Какие параметры модели будем оценивать? Прежде всего это: 1. Environmental Sound DataSet.
DataSet содержит звуковые файлы, предназначенные
для тренировки и проверки моделей.
Файлы в этом наборе включают самые разнообразные звуки, встречающие в природе:
шум дождя или ветра, лай собаки, падение капель воды и так далее.
Ограничим Environmental Sound DataSet двадцатью классами, для начала этого вполне достаточно.
Вот примеры звучания некоторых файлов.
2. Тренировка и проверка модели.
Запустим Sound Classifier и выполним тренировку модели.
По окончании работы программа выведет результаты, часть которых, показана на следущем рисунке.
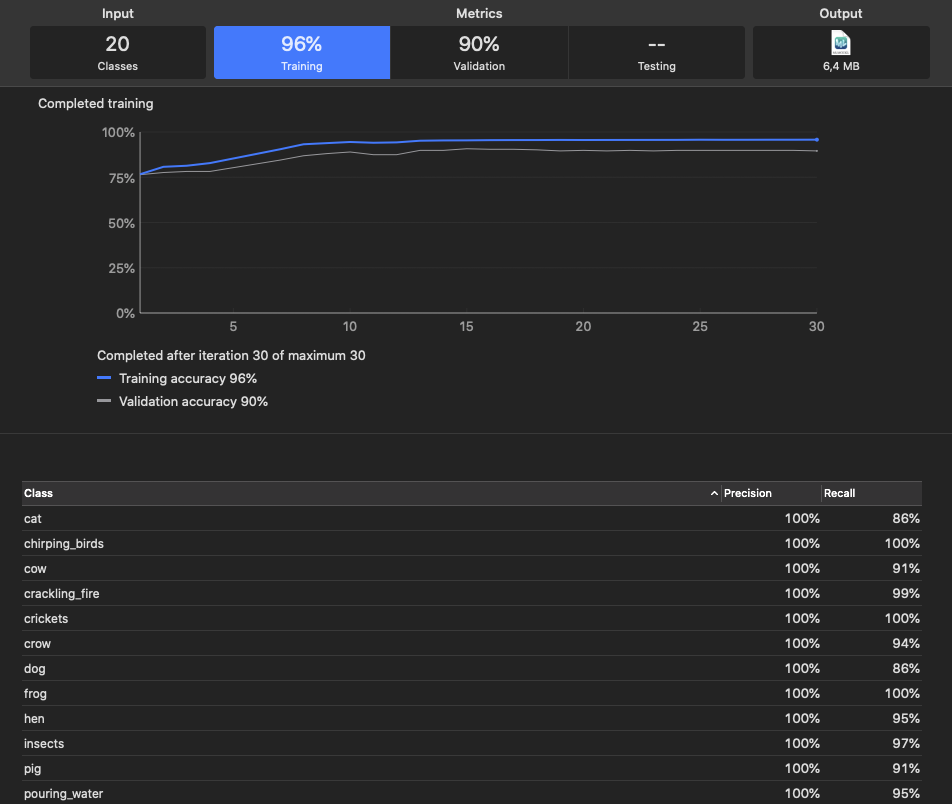 Рис. 1.
Значения Pecision и
Recall характеризуют качество модели для каждого класса.
Определения этих показателей были даны в в статье
"Create ML. Трансферное обучение", поэтому останавливаться на них я не буду.
Обратите внимание на то, что это значения для этапа тренировки модели.
Для Validation значения будут несколько хуже.
Рассмотрим вкладки в верхней части изображения.
Input. Здесь пользователь определяет путь к папкам с входными данными.
Каждая папка должна содержать звуковые файлы одного класса. Программа проверяет корректность структуры папок.
В данном случае программа нашла 20 классов.
Training. На эту вкладку Sound Classifier выведет показатель точности работы модели после training (тренировки).
Validation. Сюда Sound Classifier выведет показатель точности работы модели после Validation (проверки).
В этом разделе пользователь может самостоятельно определить множество звуков для проверки.
Если это не сделано, то Sound Classifier сам выделит часть файлов из входного множеста.
На этом подмножестве модель не тренируется, но проверяется.
Testing. На этой владке для тестирования модели пользователь может определить путь к своему множеству файлов.
В этом случае Sound Classifier после тренировки и проверки запустит тестирование модели на этом множестве.
Если это множество не определено, процесс создания модели будет закончен.
Output. На эту вкладку Sound Classifier помещает файл с готовой моделью.
3. Прослушивание звуковых файлов.
В Sound Classifier предусмотрена возможность прослушивания
любого звукового файл с одновременной
классификацией его по принадлежности. Пример показан на рисунок ниже.
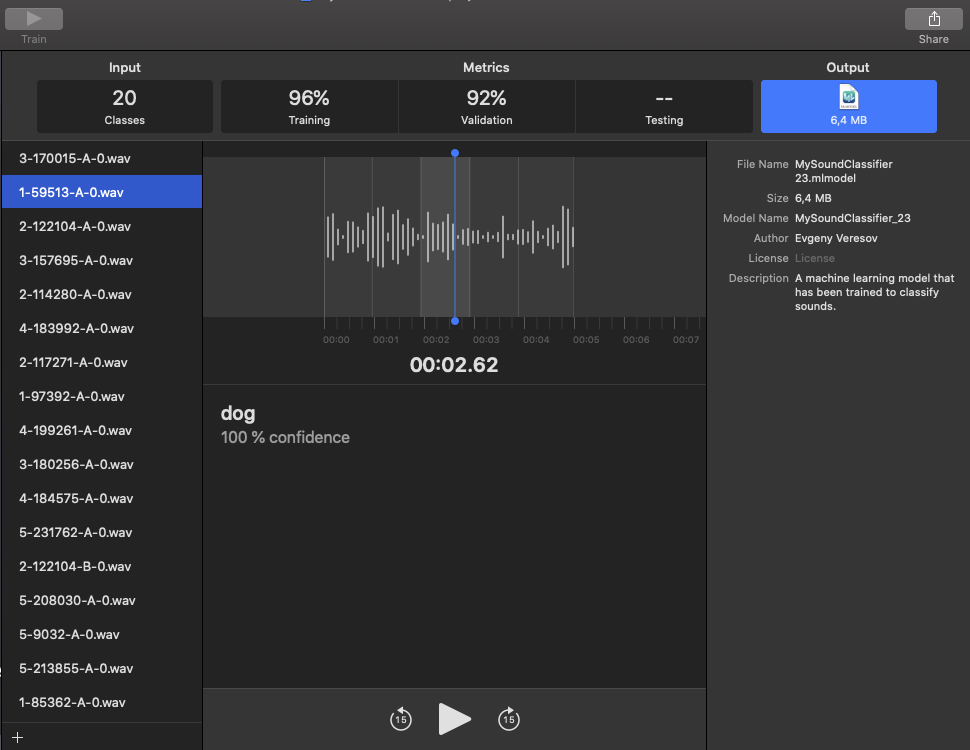
Рис. 2.
Чтобы запустить этот режим следует выполнить следующие действия:
4. Входные данные с микрофона.
Sound Classifier предусматривает возможность классификации входных звуков, поступающих с микрофона
без создания отдельного приложения. Другими словами, модель после ее создания может воспринимать и классифицировать звуки
с микрофона на компьютере разработки. Изображение экрана показано ниже.
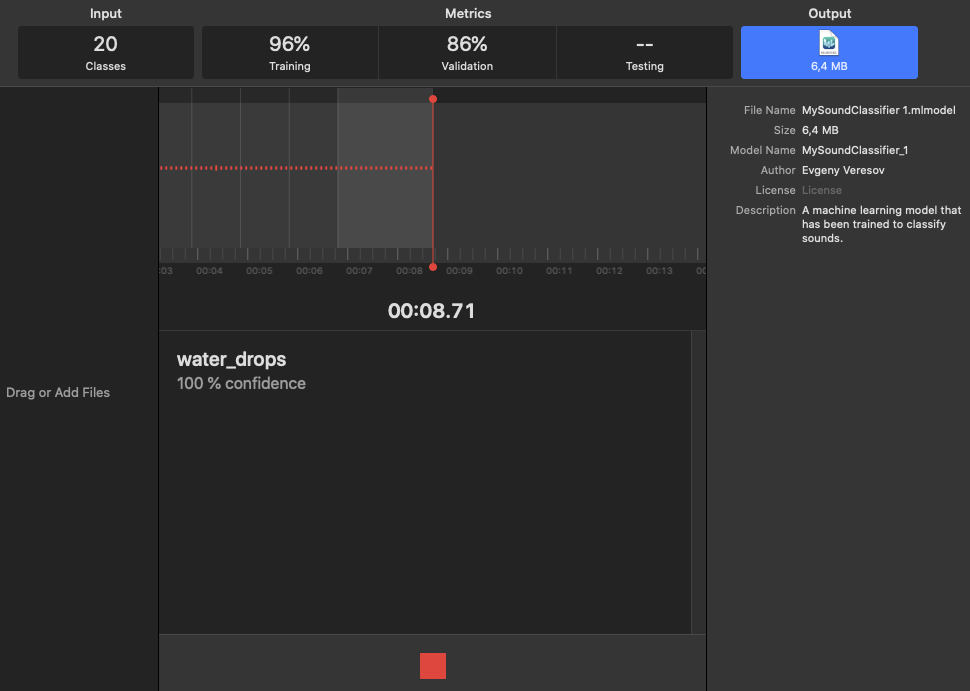
Рис. 3.
Можно ли применять Sound Classifier для обучения распознавания речи? Нет. Для этого существуют другие инструменты. Подведем итоги.
1. Размер нашей модели не велик и равен 6,4 MB.
2. Время тренировки при 30 проходах составило 4 минуты 30 секунд.
3. Качество модели вполне удолетворительное, смотрите значения на рисунке 1.
4. Инструментарий Sound Classifier возможно более развит по сравнению Image Classifier и Object Detector.
Евгений Вересов.
10.05.2020 года.
|

|
|
