|
Create ML. Object Detector.
В статье рассказано о программе Object Detector (детектор объектов), входящей
в состав Create ML. Create ML - это инструмент создания моделей Machine Learning (машинного обучения) от компании Apple.
Возьмем DataSet (набор данных) Gun Detection и протестируем программу на нем.
Это набор данных с сайта Kagle, предназначенный для тренировки моделей, используемых в приложениях для обнаружения оружия.
Usability у этого DataSet 9.4.
DataSet содержит 3000 изображений пистолетов и столько-же файлов аннотаций формата txt. Но Object Detector требует один файл аннотаций в формате json. Для решения этой проблемы была написана программа, которая собрала данные из всех txt файлов и сформировала единый файл формата json. Файл аннотаций можно загрузить. Запустим Object Detector и создадим модель для нашего набора данных. По завершении задачи оценим качество модели. Какие параметры модели будем оценивать? Прежде всего это: 1. Gun Detection DataSet.
DataSet содержит изображения для тренировки и проверки модели.
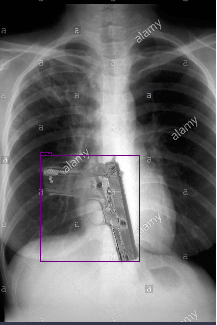
Изображения в этом наборе - это пистолеты, встречающие в самых разных обстоятельствах:
в руках стрелка, в чемоданах, под одеждой или просто на столе.
Каждое изображение может содержать один или несколько фрагментов с пистолетами. Место фрагмента на изображении локализуется
в файле аннотаций.
Размер изображений не фиксирован, цвет RGB. Набор оформлен в виде множества jpg файлов.
Число изображений — 3000, число классов - 1.
Вот примеры некоторых изображений.
Рис. 1.
2. Файл аннотаций. Для чего он нужен?
Ниже показан фрагмент файла аннотаций для DataSet Gun Detection.
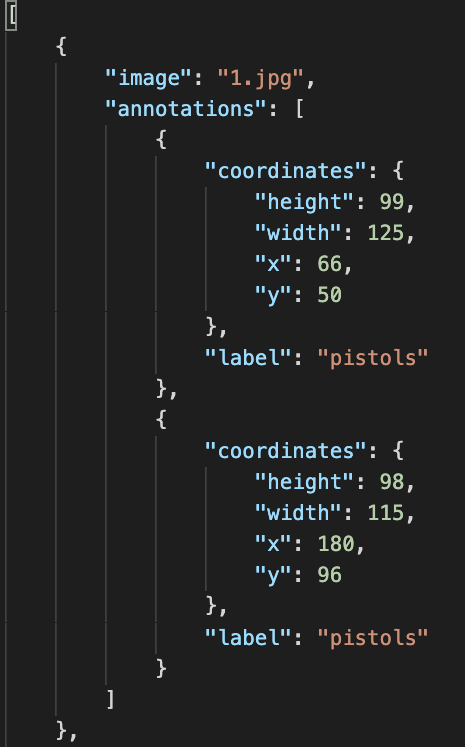 Рис. 2.
Структура файла проста. Например, cтрока "image": "1.jpg" говорит о том, что изображение находится в файле 1.jpg.
Следующая строка определяет аннотацию для двух фрагментов (прямоугольников) на изображении.
Каждый фрагмент имеет координаты центра x, у и высоту, ширину (height, width) прямоугольника.
Данная аннотация определяет (локализует) два фрагмента на изображении, которое находится в файле 1.jpg.
Файл аннотаци нужен для того, чтобы локализовать фрагменты изображений на которых будет тренироваться (обучаться) и проверяться модель. 3. Тренировка и проверка модели.
Запустим Object Detector и выполним тренировку модели.
По окончании работы программа выведет результаты показанные на следущем изображении:
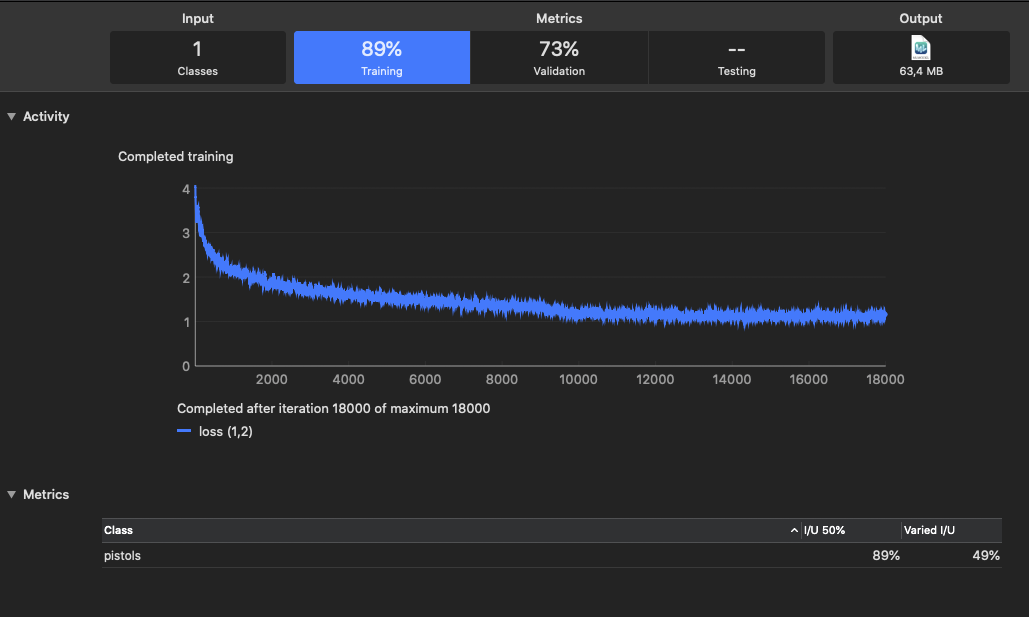 Рис. 3. Рассмотрим вкладки в верхней части изображения:
Input. Здесь пользователь определяет путь к папке с входными данными.
Папка должна содержать изображения и файл аннотаций;
Training. На эту вкладку Create ML выведет показатель точности работы модели после training (тренировки);
Validation.
Сюда Create ML выведет показатель точности работы модели после Validation (проверки).
В этом разделе пользователь может самостоятельно определить множество изображений для проверки.
Если это не сделано, то Create ML сам выделит часть изображений из входного множеста.
На этом подмножестве модель не тренируется, но проверяется.
Testing. На этой владке для тестирования модели пользователь может определить свое множество изображений.
В этом случае Create ML после тренировки и проверки запустит тестирование модели на этом множестве.
Если это множество не определено, процесс создания модели будет закончен.
Output. На эту вкладку Create ML помещает файл с готовой моделью.
Расскажем о параметре: I/U 50% , он находиться в правом нижнем углу рисунка. Это сокращение расшифровывается как Intersection-over-Union (пересечение через обьединение). Параметр определяет точность прогноза моделью. Но как вычислить насколько точно модель спрогнозировала прямоугольник опознаваемого обьекта по отношению к прямоугольнику, определенному в файле аннотаций? Делают это следующим образом: вычисляют площадь пересечения между двумя ограничивающими прямоугольниками и делят ее на их общую площадь. Число выражают в процентах. Чем больше похожи эти два прямоугольника, тем выше это число. Принято считать, что если I/U > 50%, то модель работает хорошо. Loss Function (функция потерь). График функции показан в центре изображения. В Ob]ect Dtector эта функция отражает два типа потерь: Подведем итоги.
1. Обратите внимание на существенно возросший размер модели по сравнению с Image Classifier.
Размер нашей модели составил 63,4 MB.
2. Резко возросло по сравнению с Image Classifier время тренировки. Для 18000 итераций время на CPU
составило 36 часов 48 минут.
3. У компании Apple есть еще один инструмент Deep Learning - это Turi Create. Возможно, этот
инструмент более гибок чем Create ML. Но это мир совсем других программ: Python, Анасонда, Pandas и так далее.
Евгений Вересов.
15.04.2020 года.
|

|
|